负载均衡
针对不同的网络服务需求和服务器配置,IPVS调度器实现了如下八种负载调度算法:
(1)轮叫(Round Robin)
调度器通过”轮叫”调度算法将外部请求按顺序轮流分配到集群中的真实服务器上,它均等地对待每一台服务器,而不管服务器上实际的连接数和系统负载。
(2)加权轮叫(Weighted Round Robin)
调度器通过”加权轮叫”调度算法根据真实服务器的不同处理能力来调度访问请求。这样可以保证处理能力强的服务器处理更多的访问流量。调度器可以自动问询真实服务器的负载情况,并动态地调整其权值。
(3)最少链接(Least Connections)
调度器通过”最少连接”调度算法动态地将网络请求调度到已建立的链接数最少的服务器上。如果集群系统的真实服务器具有相近的系统性能,采用”最小连接”调度算法可以较好地均衡负载。
(4)加权最少链接(Weighted Least Connections)
在集群系统中的服务器性能差异较大的情况下,调度器采用”加权最少链接”调度算法优化负载均衡性能,具有较高权值的服务器将承受较大比例的活动连接负载。调度器可以自动问询真实服务器的负载情况,并动态地调整其权值。
(5)基于局部性的最少链接(Locality-Based Least Connections)
“基于局部性的最少链接” 调度算法是针对目标IP地址的负载均衡,目前主要用于Cache集群系统。该算法根据请求的目标IP地址找出该目标IP地址最近使用的服务器,若该服务器 是可用的且没有超载,将请求发送到该服务器;若服务器不存在,或者该服务器超载且有服务器处于一半的工作负载,则用”最少链接”的原则选出一个可用的服务 器,将请求发送到该服务器。
(6)带复制的基于局部性最少链接(Locality-Based Least Connections with Replication)
“带复制的基于局部性最少链接”调度算法也是针对目标IP地址的负载均衡,目前主要用于Cache集群系统。它与LBLC算法的不同之处是它要维护从一个 目标IP地址到一组服务器的映射,而LBLC算法维护从一个目标IP地址到一台服务器的映射。该算法根据请求的目标IP地址找出该目标IP地址对应的服务 器组,按”最小连接”原则从服务器组中选出一台服务器,若服务器没有超载,将请求发送到该服务器,若服务器超载;则按”最小连接”原则从这个集群中选出一 台服务器,将该服务器加入到服务器组中,将请求发送到该服务器。同时,当该服务器组有一段时间没有被修改,将最忙的服务器从服务器组中删除,以降低复制的 程度。
(7)目标地址散列(Destination Hashing)
“目标地址散列”调度算法根据请求的目标IP地址,作为散列键(Hash Key)从静态分配的散列表找出对应的服务器,若该服务器是可用的且未超载,将请求发送到该服务器,否则返回空。
(8)源地址散列(Source Hashing)
“源地址散列”调度算法根据请求的源IP地址,作为散列键(Hash Key)从静态分配的散列表找出对应的服务器,若该服务器是可用的且未超载,将请求发送到该服务器,否则返回空
大数据题型
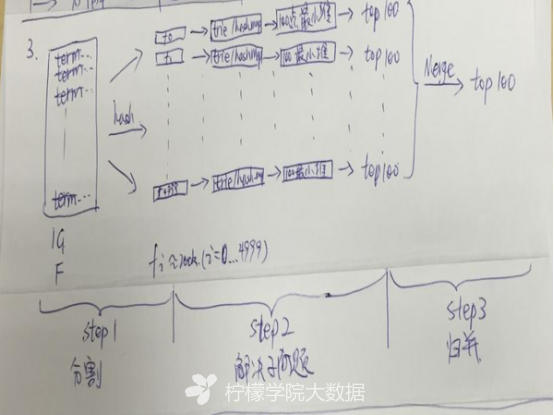
2.有一个1G大小的一个文件,里面每一行是一个词,词的大小不超过16字节,内存限制大小是1M,要求返回频数最高的100个词。
Step1:顺序读文件中,对于每个词x,取hash(x)%5000,然后按照该值存到5000个小文件(记为f0,f1,…,f4999)中,这样每个文件大概是200k左右,如果其中的有的文件超过了1M大小,还可以按照类似的方法继续往下分,直到分解得到的小文件的大小都不超过1M;
Step2:对每个小文件,统计每个文件中出现的词以及相应的频率(可以采用trie树/hash_map等),并取出出现频率最大的100个词(可以用含100个结点的最小堆),并把100词及相应的频率存入文件,这样又得到了5000个文件;
Step3:把这5000个文件进行归并(类似与归并排序);
草图如下(分割大问题,求解小问题,归并):
17.在2.5亿个整数中找出不重复的整数,注,内存不足以容纳这2.5亿个整数。
方案1:采用2-Bitmap(每个数分配2bit,00表示不存在,01表示出现一次,10表示多次,11无意义)进行,共需内存2^32*2bit=1GB内存,还可以接受。然后扫描这2.5亿个整数,查看Bitmap中相对应位,如果是00变01,01变10,10保持不变。所描完事后,查看bitmap,把对应位是01的整数输出即可。
方案2:也可采用与第1题类似的方法,进行划分小文件的方法。然后在小文件中找出不重复的整数,并排序。然后再进行归并,注意去除重复的元素。
18.腾讯面试题:给40亿个不重复的unsignedint的整数,没排过序的,然后再给一个数,如何快速判断这个数是否在那40亿个数当中?
与上第6题类似,我的第一反应时快速排序+二分查找。以下是其它更好的方法:
方案1:oo,申请512M的内存,一个bit位代表一个unsignedint值。读入40亿个数,设置相应的bit位,读入要查询的数,查看相应bit位是否为1,为1表示存在,为0表示不存在。
dizengrong:
方案2:这个问题在《编程珠玑》里有很好的描述,大家可以参考下面的思路,探讨一下:
又因为2^32为40亿多,所以给定一个数可能在,也可能不在其中;
这里我们把40亿个数中的每一个用32位的二进制来表示
假设这40亿个数开始放在一个文件中。
然后将这40亿个数分成两类:
1.最高位为0
2.最高位为1
并将这两类分别写入到两个文件中,其中一个文件中数的个数<=20亿,而另一个>=20亿(这相当于折半了);
与要查找的数的最高位比较并接着进入相应的文件再查找
再然后把这个文件为又分成两类:
1.次最高位为0
2.次最高位为1
并将这两类分别写入到两个文件中,其中一个文件中数的个数<=10亿,而另一个>=10亿(这相当于折半了);
与要查找的数的次最高位比较并接着进入相应的文件再查找。
…….
以此类推,就可以找到了,而且时间复杂度为O(logn),方案2完。